

Introduction
90% of today’s data has been created in the last two years only. According to Domo, our current data output is roughly 2.5 quintillion bytes per day. As you can imagine, there is a lot of data generated every minute. Over the years, and through technological evolution, data has become an essential topic and a key factor to business success. Especially, processing them the right way has become a crucial solution for many businesses around the world. But before we dive into this topic, let us first start with the basics. What is data?
Big Data And Problems Dealing With Them
When you look for a definition of data on the internet, you will get tons of different ones. But for our purposes, we will stick with the definition of data as raw or unprocessed information. In the past few decades, these raw and unprocessed information gained more and more traction because companies realized that these data could change the way we live, work and think. Just think about all the data that every business already owns! And so, the buzz around big data started.
However, businesses also realized that the gigantic amount of raw and unprocessed information itself wasn’t of big value until they could be structured, analyzed, and interpreted well. Only well analyzed and interpreted data could give powerful business and market insights. And the big problem that was identified was: with traditional tools, such as classic ETL it was impossible to organize and structure the big data in a way that they can be quickly and easily accessed for analyses.
Data integration solutions were designed to meet the biggest part of an organization’s BI requirements. To fulfill this, some ETL vendors are extending their product lines horizontally by data tools and features to capture real time data to provide a complete data management solution. Then there are others that extend vertically by adding more features in order to provide a complete business intelligence solution.
The Evolution Of ETL
In order to benefit from all the data, data warehouses and ETL tools were invented. Many ETL tools were originally developed to ease the development of data warehouse and thereby more enjoyable. Today, the top ETL tools in the market have vastly expanded their functionality for data profiling, data cleansing, Enterprise Application Integration (EAI), big data processing, data governance and master data management. Once the data is available in a data warehouse or OLAP (online analytical processing) cube, BI software is commonly used to analyze and visualize them. BI software also helps you with reporting, data discovery, data mining and dash boarding.
But what are data warehouse and ETL exactly? Over the years, many different understandings of these two terms have evolved. Hence, let’s set a common ground for this article first. The most common definition for data warehouse in the market is: A system that extracts, cleans, conforms, and delivers source data into a target storage so they be used for queries and analysis. The main task is to deliver reliable and accurate data that can be used for crucial business decisions. In order to achieve that, data from one or more operational system needs to be extracted and copied into the data warehouse, which is done by ETL tools.
ETL is the abbreviation for Extract, Transform and Load. And what these tools basically do is to pull out data from one or even multiple database(s) and place them in one database, the so-called target storage.
How Does The ETL Process Work?
Extract
The extract step covers the data extraction from multiple source systems and the preparation of the data for the next steps. The main objective of this step is to retrieve all the required data from the source systems with as little resources as possible. The extract step is supposed to be designed in such a way that it does not negatively affect the source system in terms of performance and response time.
Transform
The transform step applies a set of rules to transform the data from the source to the target. This includes converting all extracted data to the same dimension using the same units so that they can later be joined together. The transformation step also gathers data from several sources, generating new calculated values and applying advanced validation rules.
Load
During the loading step, it is necessary to ensure that the load is performed correctly and with as little resources as possible. During the loading process the data is written into the target database.

What Are The Benefits Of ETL?
The main benefit of ETL is that it is much easier and faster to use than traditional methods that move data by manually writing codes. ETL tools contain graphical interfaces which speed up the process of mapping tables and columns between the source and target storages.
Below are some key advantages of ETL tools:
Ease of Use through Automated Processes
As already mentioned in the beginning, the biggest advantage of ETL tools is the ease of use. After you choose the data sources, the tool automatically identifies the types and formats of the data, sets the rules how the data has to be extracted and processed and finally, loads the data into the target storage. This makes coding in a traditional sense where you have to write every single procedure and code unnecessary.
Visual flow
ETL tools are based on graphical user interface (GUI) and offer a visual flow of the system’s logic. The GUI enables you to use the drag and drop function to visualize the data process.
Operational resilience
Many data warehouses are fragile during operation. ETL tools have a built-in error handling functionality which help data engineers to develop a resilient and well instrumented ETL process.
Good for complex data management situations
ETL tools are great to move large volumes of data and transfer them in batches. In case of complicated rules and transformations, ETL tools simplify the task and assist you with data analysis, string manipulation, data changes and integration of multiple data sets.
Advanced data profiling and cleansing
The advanced functions refer to the transformation needs which are common to occur in a structurally complex data warehouse.
Enhanced business intelligence
Data access is easier/better with ETL tools as it simplifies the process of extracting, transforming and loading. Improved access to information directly impacts the strategic and operational decisions that are based on data driven facts. ETL tools also enable business leaders to retrieve information based on their specific needs and make decisions accordingly.
High return on investment (ROI)
ETL tools helps business to save costs and thereby, generate higher revenues. In fact, a study that was conducted by the International Data Corporation has revealed that the implementation of ETL resulted in a median 5-year ROI of 112% with a mean payback of 1.6 years.
Performance
ETL tools simplify the process of building a high-quality data warehouse. Moreover, several ETL tools come with performance enhancing technologies. For example, like Cluster Awareness applications which are actually software applications designed to call cluster APIs in order to determine its running state, in case a manual failover is triggered between cluster nodes for planned technical maintenance, or an automatic failover is required, if a computing cluster node encounters hardware.
ETL Issues
The benefits that we have elaborated above are all related to traditional ETL. However, traditional ETL tools cannot keep up with the high speed of changes that is dominating the big data industry. Let’s take a look at the shortcomings of these traditional ETL tools.
Traditional ETL tools are highly time-consuming. Processing data with ETL means to develop a process in multiple steps every time data needs to get moved and transformed. Furthermore, traditional ETL tools are inflexible for changes and cannot load readable live-data into the BI front end. We also have to mention the fact that it is not only a costly process but also time consuming. And we all know that time is money.
There are some factors that influence the function of ETL tools and processes. These factors would be divided in the following categories:
Data Architecture Issues
Similarity of Source and Target Data Structures:
The more the source data structure differ from the one of the target data, the more complex the traditional ETL processing and maintenance effort become. Due to the different structures, the load process will typically have to parse the records, transform values, validate values, substitute code values etc.
Quality of Data:
Common data quality issues include missing values, code values not correct list of values, dates and referential integrity issues. It makes no sense to load the data warehouse with poor quality data. As an example, if the data warehouse will be used for database marketing, the addresses should be validated to avoid returned email.
Complexity of the Source Data:
Depending on the sourcing teams background, some data sources are more complex than others. Examples of complex sources may include multiple record types, bit fields and packed decimal fields. This kind of data will translate into requirements of the ETL tool or custom written solution since they are unlikely to exist in the target data structures. Individuals on the sourcing team that are unfamiliar with these types may need to do some research in these areas.
Dependencies in the Data:
Dependencies in the data will determine the order in which you load tables. Dependencies also tend to reduce parallel loading operations, especially if data is merged from different systems, which are on a different business cycle. Complex dependencies will also tend to make to load processes more complex, encourage bottlenecks and make support more difficult.
Meta Data:
Technical meta data describes not only the structure and format of the source and target data sources, but also the mapping and transformation rules between them. Meta data should be visible and usable to both programs and people.
Application Architecture Issues
Logging:
ETL processes should log information about the data sources they read, transform and write. Key information includes date processed, number of rows read and written, error that encountered, and rules applied. This information is critical for quality assurance and serves as an audit trail. The logging process should be rigorous enough so that you can trace data in the data warehouse back to the source. In addition, this information should be available as the processes are running to assist in the completion times.
Notification:
The ETL requirements should specify what makes an acceptable load. The ETL process should notify the appropriate support people when a load fails or has errors. Ideally, the notification process should plug into your existing error tracking system.
Cold start, warm start:
Unfortunately, systems do crash. You need to be able to take the appropriate action if the system crashes with your ETL process running. Partial loads can be literally a pain. Depending on the size of your data warehouse and volume data, you want to start over, known as cold start, or start from the last known successfully loaded records, known as warm-start. The logging process should provide you information about the state of the ETL process.
People Issues
Management’s comfort level with technology:
How conversant is your management with data warehousing architecture? Will you have a data warehouse manager? Does management have development in the background? They may suggest doing all the ETL processes with Visual Basic. Comfort level is a valid concern, and these concerns will constrain your option.
In-House expertise:
What is your businesses tradition? SQL server? ETL solutions will be drawn from current conceptions, skills and toolsets. Acquiring, transforming and loading the data warehouse is an ongoing process and will need to be maintained and extended as more subject areas are added to the data warehouse.
Support:
Once the ETL processes have been created, support for them, ideally, you should plug into an existing support structures, including people with appropriate skills, notification mechanisms and error tracking systems. If you use a tool for ETL, the support staff may need to be trained. The ETL process should be documented, especially in the area of auditing information.
Technology Architecture Issues
Interoperability between platforms:
There must be a way for systems on one platform to talk to systems on another. FTP is a common way to transfer data from one system to another. FTP requires a physical network path from one system to another as well as the internet protocol on both systems. External data sources usually come on a floppy tape or an internet server.
Volume and frequency of loads:
Since the data warehouse is loaded with batch programs, a high volume of data will tend to reduce the batch window. The volume of data also affects the back out and recovery work. Fast load programs reduce the time it takes to load data into the data warehouse.
Disk space:
Not only does the data warehouse have requirements for a lot of disk space, but there is also a lot of hidden disk space needed for staging areas and intermediate files. For example, you may want to extract data from source systems into flat files and then transform the data to other flat files for load.
Scheduling:
Loading the data warehouse could involve hundreds of sources files, which originate on different system use different technology and produced at different times. A monthly load may be common for some portions of the warehouse and a quarterly load for others. Some loads may be on demand such as lists of products or external data. Some extract programs may be run on a different type of system than your scheduler.
ETL Tools List
In the list below, you see the most common traditional ETL tools these days:
- Oracle Warehouse Builder (OWB)
- SAP Data Services
- IBM Infosphere Information Server
- SAS Data Management
- PowerCenter Informatica
- Elixir Repertoire for Data ETL
- Data Migrator (IBI)
- SQL Server Integration Services (SSIS)
- Talend Studio for Data Integration
- Sagent Data Flow
- Alteryx
- Actian DataConnect
- Open Text Integration Center
- Oracle Data Integrator (ODI)
- Cognos Data Manager
- Microsoft SQL Server Integration Services (MSSIS)
- CloverETL
- Centerprise Data Integrator
- IBM Infosphere Warehouse Edition
- Pentaho Data Integration
- Adeptia Integration Server
- Syncsort DMX
- QlikView Expressor
- Realtional Junction ETL Manager (Sesame Software)
Implementation Of ETL
Organizations with already well-defined IT practices are at an innovative stage to create the next level of technology transformation, by constructing their own data warehouse to store and monitor real-time data. We need to explain in detail how each step of the ETL process can be performed.
The first part of an ETL process involves extracting the data from the source system(s). In many cases, this represents the most important aspect of ETL, since extracting data correctly sets the stage for the success of subsequent processes.
There are several ways to perform the extracting step:
- Update notification: if the source system is able to provide a notification that a record has been changed and describe the change
- Incremental extract: some systems may not be able to provide notification that an update has occurred, but they are able to identify which records have been modified and provide an extract of such records. During further ETL steps, the system needs to identify changes and propagate it down. Note, that by using daily extract, you may not be able to handle deleted records properly
- Full extract: some systems are not able to identify which data has been changed at all, so a full extract is the only way you can get the data out of the system. The full extract requires keeping a copy of the last extract in the same format in order to be able to identify changes.
In the data transformation stage, a series of rules or functions are applied to the extracted data in order to prepare it for loading into the end target storage.
Transforming the data involves the following tasks:
- Applying business rules
- Cleaning the data
- Filtering the data
- Splitting a column into multiple columns
- Joining together data from multiple sources
- Transposing rows and columns
- Applying any kind of simple or complex data validation
The loading process loads the data into the target storage, which may be a simple flat file or a data warehouse. Depending on the requirements of the organization, this process varies widely. As the load phase interacts with a target storage, the constraints defined in the target storage schema, as well as in triggers activated upon data load, and application of that data load, also contribute to the overall data quality performance of the ETL process.
Use ETL Tools To Improve Your Business Processes
ETL is an important part of today’s business intelligence. ETL is every businesses process from which data from disparate sources can be put in one place to programmatically analyze and discover business insights. The adoption of an integrated strategy with the help of ETL tools and processes, actually gives a business a competitive advantage, since it will be able to use its data in such a way and then make data driven decisions. But why an ETL process is in fact so important? Simply said: it adds value to data. That happens by documenting measures of confidence in data, capturing the flow of transactional data, adjusting data from multiple sources, structuring data to BI tools and enabling subsequent analytical data processing.
According to Harvard Business Review, you don’t need to make enormous up-front investments in IT to use big data with ETL tools. Here’s an approach to building a capability from scratch:
- Pick a business unit to be testing the ground. It should have a quant-friendly leader backed up by a team of data scientists;
- Challenge each key function to identify five business opportunities based on big data, each of which could be prototyped within five weeks by a team of no more than five people;
- Implement a process of innovation that includes four steps: experimentation, measurement, sharing and replication;
- Keep in mind Joy’s Law: Most of the smartest people work for someone else. Open some of your data sets and analytics challenges to interested parties across the internet.
Things That Usually Go Wrong With An ETL Project
According to Spaceworks, tech projects tend to go over time and over budget. Specifically, 45% over budget, 7% over time and 56% less value than predicted. Your ETL project will probably not be immune. Here are the most common mistakes that occur with an ETL project:
- Forgetting about long-term maintenance
- Underestimating data transformation requirements
- Foregoing the customer development process
- Tightly connecting different elements of your data pipeline
- Building your ETL process based on your current data scale
- Not recognizing the warning signs
- Focusing on tools and technologies rather than fundamental practices
Importance Of ETL Testing
ETL testing can be performed either manually or by using tools like Informatica, Querysurge, etc. However, the biggest part of the ETL testing process is executed by SQL scripting or eyeballing of data on spreadsheets. The usage of automated testing tools ensures that only trusted data will be delivered on your system. The types of testing that can be done with ETL tools include unit, functional, regression, continuous integration, operational monitoring and more. Coming to the benefits, your business can reduce testing time by 50% to 90% and also reduce resource utilization. ETL testing lower business risks and instils confidence in the data.
ETL testing plays a significant role in verifying, validating and ensuring that the business information is exact, consistent and reliable. Part of ETL testing is data centric testing, in which large data volumes are compared across heterogeneous data sources. This data centric testing helps in achieving high quality of data by getting the erroneous processes fixed quickly and effectively. ETL and data warehouse testing should be followed by impact analysis and should focus on strong alignment between development, operations and the teams in the company.
Types Of ETL Testing
The types of ETL testing are the following:
- Data centric testing: is about testing the quality of data. The objective of the data centric testing is to ensure that valid and correct data is in the system. It ensures that ETL processes are applied properly on source database which transform and load data in the target database. It further ensures that proper system migration and upgrades are performed.
- Data accuracy testing: ensures that the data is accurately transformed and loaded as expected. Through this testing, you can identify errors obtained due to truncation of characters, improper mapping of columns and implementation errors in logic.
- Data completeness testing: verifies that all the expected data is loaded in your target storage from all your data sources. It helps to verify that the count of rows in driving table matches with the one in the target table.
- Data integrity testing: helps to check the counts of ‘unspecified’ or ‘unmatched’ rows.
- Business testing: ensures that the data fulfills the critical business requirements.
- Data transformation testing: is more or less the same as business testing. But, this test also checks whether the data have been moved, copied and loaded completely and accurately.
- Production validation testing: is done on many cases as it cannot be achieved by writing source SQL queries and comparing them with the output to the target.
ETL Testing Issues
Businesses have to realize the need to test data in order to ensure data completeness and data integrity. They have also need to realize the fact that comprehensive testing of data at every point throughout the ETL process is important and inevitable, as more data is collected and used for strategic decision making that affects their business forecast. However, various strategies are very time-consuming, resource-intensive, and inefficient. Thus, a well-planned, well defined and effective ETL testing scope is necessary to guarantee smooth conversions of the project to the final production phase. It is time now for us to see some of the issues that are common with ETL and Data Warehouse testing.
Some of the important ETL and Data Warehousing testing challenges are:
- Unavailability of inclusive test bed at times
- Lack of proper flow of business information
- Potential loss of data during the ETL process
- Existence of many ambiguous software requirements
- Existence of apparent trouble acquiring and building test data
- Production sample data is not a true representation of all possible business processes
- Certain testing strategies are time consuming
- Checking data completeness for transformed columns is a tricky process
The Need For Another Solution
In this digital era, new requirements arise faster than ever before, and previous requirements change so quickly that agility and responsiveness became two essential factors for success. Because of issues like the ones that were already mentioned above, traditional data warehouses simply cannot cope with the needs of today’s businesses and related overall digital transformation trends. Because of the shortcomings of the traditional ETL tools approach, new approaches to data processing emerged was the next generation ETL, whereas in detail called automated ETL processes. By leveraging the latest technologies in ETL tools, enterprises are achieving remarkable results such as: doubling productivity through unified data integration, a twofold reduction in costs from greater overall efficiency and optimized resource utilization across a variety of projects, and quantifiable business impact in such areas as revenue, lower business costs, customer retention and more precious time to focus on the main market. That next generation ETL, was offered by Germany’s fastest growing start up, Data Virtuality GmbH with solutions such as Data Virtuality Platform, DataVirtuality Pipes and Data Virtuality Pipes Professional.
About Data Virtuality
Data Virtuality develops and distributes the software Data Virtuality Platform, which affords companies an especially simple means of integrating and connecting a variety of data and applications. The solution is revolutionizing the technological concept of data virtualization and generates a data warehouse consisting of relational and non-relational data sources in just a few days. By using integrated connectors, the data can be immediately processed in analysis, planning or statistics tools or written back to source systems as needed. The data warehouse also automatically adjusts to changes in the IT landscape and user behavior, which lends companies using Data Virtuality the highest possible degree of flexibility and swiftness with minimum administrative overhead. Founded in 2012, prior 8 years of research, by Dr. Nick Golovin, with offices in Leipzig, Frankfurt am Main and San Francisco, the company originated from a research initiative of the chair of information technology at the university of Leipzig and is financed by Technologiegründerfonds Sachsen (TGFS) and High Tech Gründerfonds (HTGF). In addition, Data Virtuality was honored vendor for Gartner in 2016 and for Forrester Research Inc., in 2017.

Data Virtuality’s data integration solutions enable detailed insights from real time and historical data with any BI tool. By combining data virtualization with an automated ETL engine, customers benefit from reducing their data integration effort by 80% and enabling companies to focus on their core business. It provides agile data integration for data champions.
Data Virtuality Pipes & Pipes Professional
Pipes Is a cloud data integration solution that empowers your business intelligence tools with data that matters. With Pipes, you can integrate data from several databases and APIs to any data warehouse in just 5 minutes. No coding or maintenance of APIs is required.
Pipes automatically gets data from 200+ available sources in your data warehouse. With just a few clicks and without any coding.
Pipes Professional enables you to build custom data pipelines with the best-in-class SQL editor.
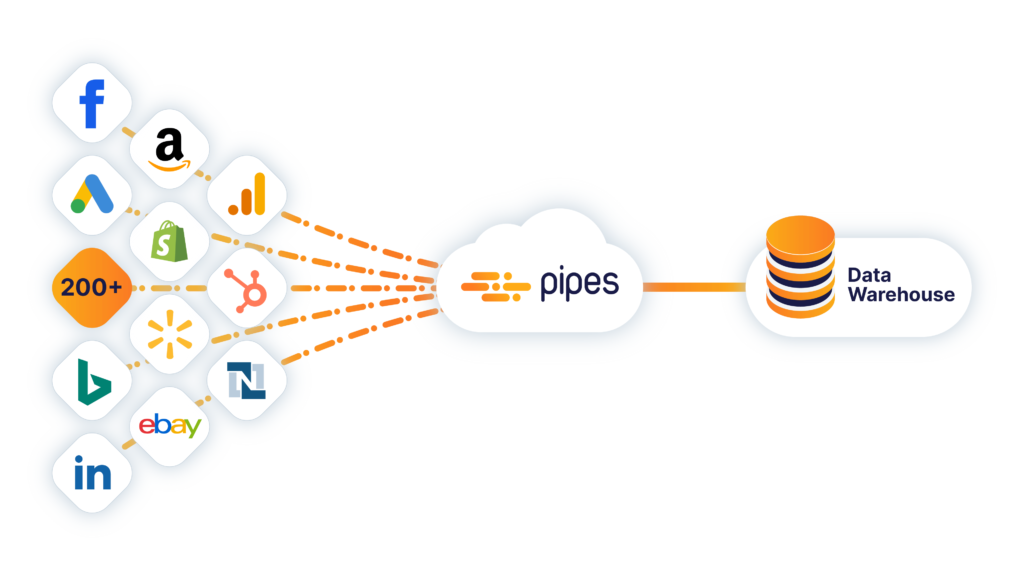
Features
- Quick Setup
- Built for big data
- Secure Connection
- EU and US hosting
- No coding required
- Pre-built templates
- Access raw data
- Managed schema
- Full control
Find out more about Data Virtuality Pipes and Pipes Professional here.
Data Virtuality Platform
Data Virtuality Platform solves a major challenge of today’s organizations across all industries: faced with an ever-increasing variety of data and cloud services, businesses are struggling to perform detailed analyses and gain insights from real-time and persisted data.
Data Virtuality Platform marries two distinct technologies to create an entirely new manner of integrating data. Combining data virtualization and next generation ETL enables an agile data infrastructure with high performance.
It connects all data sources with any business intelligence or analytics tool. The software accesses, manages and integrates any database and cloud service. By combining data virtualization and ETL processes, Data Virtuality Platform is the only solution that both enables and accelerates complex analyses highly flexible and with a minimum effort. And all that just by using only one programming language-SQL.
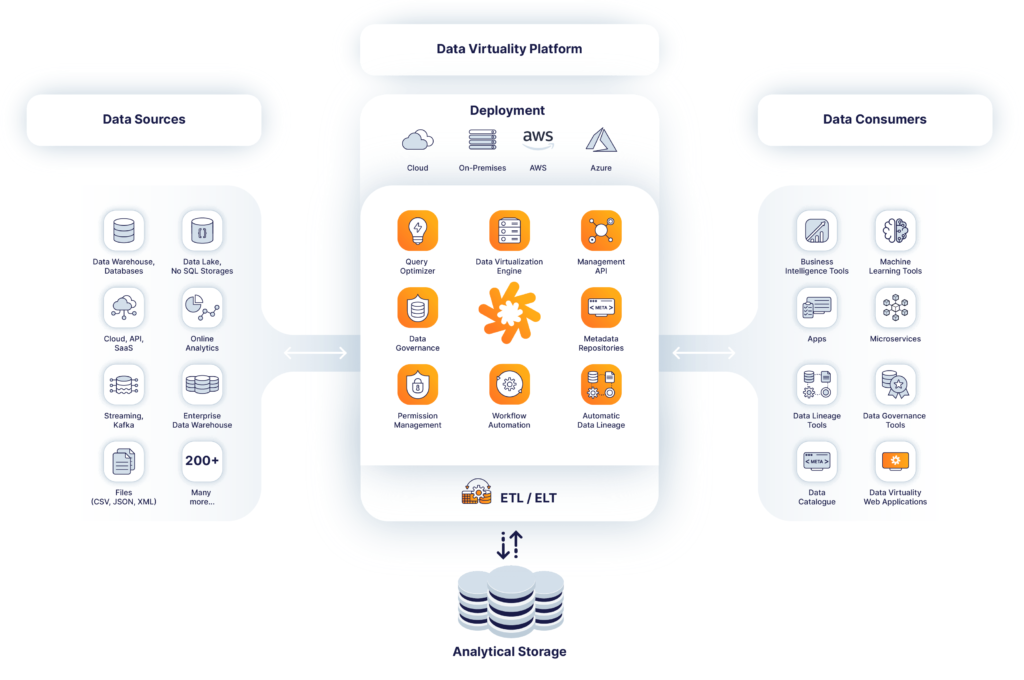
Features
- 100% project success rate
- One programming language-SQL
- Complete set up in just 1 day
- Agile data infrastructure
- Live-data
- Query data
- Write data
Find out more about Data Virtuality Platform here.
Our Company’s Story
Nick Golovin, our CEO and founder of Data Virtuality GbmH was in charge of Koch Media when their business units were digitalized and the importance of digital information grew exponentially. He quickly realized that the tools available to connect and centralize data from multiple data sources were not capable of meeting the rapidly changing needs of the business units. Nick concluded: in-house development is too slow and data integration tools available in the market are too inflexible.
Millions of data advocates face this challenge every day. In each company, there is a data advocate like Nick who desperately looks for solutions to overcome the issues that come along with this challenge. Having been in similar shoes, Nick finally paired his work experience with 8 years of academic R&D to build solutions, that we now call Data Virtuality Platform.
Last But Not Least
Every business in the world, irrespective of its size, has a vast amount of data. But these data are nothing without a powerful tool that can clean them up and make them accessible for analysis. Next generation ETL tools are the traffic cop for business intelligence applications. They control the flow of data between myriad source systems and BI applications. As data management are becoming more complex, data integration tools also need to change to keep up the pace.
So, what are you waiting for? Start using your data in the right way as soon as possible with the next generation solutions provided by Data Virtuality.
Contact us to start your 14-days free trial with Data Virtuality Pipes or schedule a demo call to learn more about Data Virtuality Platform. If you have further questions, don’t hesitate to contact us at the following email address: info@datavirtuality.com
We’d be happy to hear from you!
Other articles and guides you may find interesting
- Fully automated ETL testing: A Step-By-Step Guide, by CA Technologies, available on: https://www.techwell.com/sites/default/files/resource/download/FullyAutomatedETLTesting.pdf
- Evaluating ETL and data integration platforms, by TDWI Report Series, available on: http://download.101com.com/tdwi/research_report/2003ETLReport.pdf
- ETL evolution for real-time data warehousing, by Dr Kamal Kakish and Dr. Theresa A. Kraft, available on: https://www.researchgate.net/profile/Theresa_Kraft/publication/280837435_ETL_Evolution_for_Real-Time_Data_Warehousing/links/56008f5308ae07629e52af09.pdf
- Big Data: The management revolution, by Harvard Business Review, available on: http://tarjomefa.com/wp-content/uploads/2017/04/6539-English-TarjomeFa-1.pdf







